Материалы по тегу: pci express 6.0
|
07.02.2026 [13:53], Сергей Карасёв
Montage Technology представила активные кабели PCIe 6.x/CXL 3.xКомпания Montage Technology объявила о разработке активных электрических кабелей (AEC) PCIe 6.x/CXL 3.x, предназначенных для организации высокоскоростного интерконнекта с низкой задержкой в дата-центрах, ориентированных на ресурсоёмкие задачи ИИ и НРС. Отмечается, что на фоне стремительного внедрения ИИ и продолжающегося развития облачных вычислений быстро растёт нагрузка на ЦОД. При этом PCIe остаётся основным стандартом для обмена данными между CPU, GPU, сетевыми картами и высокопроизводительными хранилищами. Интерконнект на базе PCIe применяется как в рамках серверных стоек, так и в составе суперузлов, в связи с чем требуется увеличивать протяжённость соединений. В таких условиях, подчёркивает Montage Technology, медные линии на базе AEC имеют решающее значение для обеспечения целостности сигнала на больших расстояниях. 
Источник изображения: Montage Technology Кабели Montage Technology PCIe 6.x/CXL 3.x с ретаймером используют фирменные блоки SerDes и передовую архитектуру DSP. Применён высокоплотный форм-фактор OSFP-XD. Говорится о развитых функциях мониторинга и диагностики каналов связи, что упрощает обслуживание систем и повышает их эффективность. Возможно использование в инфраструктурах с различными топологиями. В разработке решения, как утверждается, принимали участие ведущие китайские производители кабелей. Проведены успешные тесты на совместимость с CPU, xPU, коммутаторами PCIe, сетевыми адаптерами и другими устройствами. В дальнейшем компания Montage Technology намерена развивать направление высокоскоростного интерконнекта, включая выпуск ретаймеров PCIe 7.0.
06.02.2026 [10:53], Владимир Мироненко
Без дефицитной HBM: Positron AI готовит ИИ-ускоритель Asimov с терабайтами LPDDR5xКомпания Positron AI сообщила о привлечении $230 млн инвестиций в рамках переподписанного раунда финансирования серии B, в результате которого оценка её рыночной стоимости превысила $1 млрд. Раунд возглавили ARENA Private Wealth, Jump Trading и Unless при участии новых инвесторов Qatar Investment Authority (QIA), Arm и Helena, а также существующих инвесторов Valor Equity Partners, Atreides Management, DFJ Growth, Resilience Reserve, Flume Ventures и 1517. Объявление было сделано на мероприятии Web Summit Qatar, что подчеркивает растущий международный авторитет компании, отметил ресурс eWeek. На то, чтобы перейти в категорию единорогов, Positron AI потребовалось 34 месяца. Positron AI отметила решение Jump Trading стать одним из лидеров раунда после того, как эта компания стала её клиентом. «Для рабочих нагрузок, которые нас интересуют, узкими местами всё чаще становятся память и энергопотребление, а не теоретические вычисления», — сказал технический директор Jump Trading. — В ходе наших тестов Positron Atlas показал примерно в три раза меньшую сквозную задержку, чем сопоставимая система на базе NVIDIA H100, при оценке рабочих нагрузок инференса, в готовом к производству корпусе с воздушным охлаждением и цепочкой поставок, которую мы можем спланировать». 
Источник изображения: Positron AI Полученные инвестиции позволят ускорить выход платформы следующего поколения Asimov, разработанной на заказ. Компания планирует завершить тестирование Asimov к концу III квартала, а пробные версии появятся в конце I квартала 2027 года. В Asimov будет использоваться память LPDDR (без HBM), но возможность приблизиться к теоретической пиковой пропускной способности памяти означает, что компании и не нужно полагаться на HBM для быстрой генерации токенов, сообщил ресурсу EE Times технический директор Positron. Вычислительные элементы Asimov — это эволюция блоков Atlas с добавлением ядер Arm и улучшенным интерконнектом. Расширить память LPDDR5x в Asimov можно с помощью CXL — с 864 Гбайт до 2,3 Тбайт на чип. Чип позволяет создать два независимых домена памяти, чтобы лучше утилизировать её. Хосит-интерфейс чипа — PCI 6.0 x32. Хотя LPDDR5x дешевле и ёмче HBM, она значительно уступает ей по пропускной способности. Если ускорители Rubin от NVIDIA оснащены 288 Гбайт памяти HBM4 с пиковой пропускной способностью 22 Тбайт/с, то для Asimov, по-видимому, потолок составляет около 3 Тбайт/с, пишет The Register (в спецификациях указано 2,76 Тбайт/с). По словам Positron, разница в том, что её чипы действительно могут использовать 90 % этой пропускной способности, в то время как GPU на базе HBM в реальных условиях едва достигают 30 % пиковой пропускной способности, хотя память Rubin даже в этом случае примерно в 2,4 раза быстрее, чем у Asimov. 
Источник изображения: Positron AI Компания сообщила, что 400-Вт чип оснащён систолической матрицей 512×512, работающей на частоте 2 ГГц и поддерживающей типы данных TF32, FP16/BF16, FP8, NVFP4 и INT4. Эта матрица управляется рядом ядер Armv9 и может быть переконфигурирована, например, в 128×512 (GEMV) или 512×128 (GEMM), в зависимости от того, какой вариант более выгоден для решения конкретной задачи. Четыре чипа Asimov образуют 4U-платформу Titan с воздушным охлаждением и пропускной способностью между чипами 16 Тбит/с. Компания отметила, что Asimov рассчитан на поддержку 2 Тбайт памяти на ускоритель и 8 Тбайт памяти на систему Titan с аналогичной пропускной способностью памяти, как у ускорителя NVIDIA Rubin. В масштабе стойки это означает объём памяти более 100 Тбайт. До 4096 систем Titan (16384 ускорителя) могут быть объединены в единый масштабируемый домен с более чем 32 Пбайт памяти. Это достигается с помощью чистого межчипового интерконнекта, а не коммутируемых масштабируемых сетей, как в стоечных архитектурах NVIDIA или AMD. Positron подчеркнула, что её архитектура, ориентированная на память, открывает доступ к высокоэффективным задачам инференса, включая большие языковые модели с длинным контекстом, агентные рабочие процессы и модели медиа и видео следующего поколения.
19.01.2026 [09:03], Сергей Карасёв
Panmnesia представила чип-коммутатор Panswitch с поддержкой PCIe 6.4 и CXL 3.2Южнокорейский стартап Panmnesia анонсировал чип-коммутатор Panswitch (модель H1SW06245ACFAA), предназначенный для использования в составе масштабных HPC-платформ и дата-центров, ориентированных на задачи ИИ. Кроме того, представлена сопутствующая плата для разработчиков PanRDK. Как утверждается, Panswitch — это первое в мире изделие в своём классе, полностью поддерживающее ключевые функции, описанные в спецификации CXL 3.2, включая Port-based Routing (PBR). Это позволяет соединять тысячи устройств в единой вычислительной среде посредством CXL.  Отмечается, что Panswitch даёт возможность формировать сети с различными топологиями — от простых древовидных структур до ячеистых (mesh) конфигураций, систем Dragonfly и пр. Это позволяет оптимизировать пути передачи данных в зависимости от конкретных рабочих нагрузок. В состав Panswitch входит проприетарный CXL-контроллер Panmnesia со сверхнизкой задержкой. Говорится о поддержке интерфейса PCIe 6.4. В целом, как подчёркивает разработчик, Panswitch обеспечивает повышенную производительность и эффективность при крупномасштабных развёртываниях ИИ.  В свою очередь, плата PanRDK предназначена для тестирования чипа-коммутатора в реальных условиях. Это решение оснащено FPGA, благодаря чему может быть настроено для работы в качестве различных устройств, в том числе CXL CPU, CXL GPU и пула памяти CXL. Предусмотрены слоты MCIO и CEM, что позволяет сформировать полноценную систему с поддержкой CXL. Плата совместима не только с изделиями Panmnesia, но и с широким спектром решений сторонних производителей, соответствующих стандарту CXL. Поставки чипов Panswitch и пилотных систем уже начались. 
07.01.2026 [16:47], Владимир Мироненко
В попытке догнать Broadcom: Marvell купила за $540 млн XConn, разработчика коммутаторов PCIe и CXLПосле объявления о заключении окончательного соглашения о приобретении XConn Technologies, поставщика передовых коммутаторов PCIe и CXL, акции Marvell Technology пошли в гору — их цена выросла на 4 %, сообщил ресурс SiliconANGLE. Сумма сделки составляет около $540 млн. Примерно 60 % будет выплачено наличными и 40 % — акциями Marvell, при этом стоимость последних будет определяться на основе средневзвешенной цены за 20 дней. По словам Marvell, приобретение позволит ей расширить портфель коммутационных решений продуктами XConn PCIe и CXL, а также укрепить команду по разработке решений UALink высококвалифицированными инженерами XConn с глубокими знаниями в области высокопроизводительной коммутации. Коммутация необходима для соединения большого количества ИИ-микросхем в гигантские кластеры для запуска мощных больших языковых моделей. Компания XConn, основанная в 2020 году и финансируемая частными инвесторами, выпустила в марте 2024 года первый в отрасли коммутатор Apollo с поддержкой CXL 2.0 и PCIe 5.0, обеспечивающий 256 линий. Его выпускает TSMC с использованием техпроцессов N16 и N5, сообщил ресурс Data Center Dynamics. Затем она выпустила в марте 2025 года гибридный коммутатор Apollo 2, объединяющий CXL 3.1 и PCIe 6.2 на одном чипе в конфигурациях от 64 до 260 линий. 
Источник изображения: Marvell Когда-то Marvell считалась одной из самых перспективных компаний после NVIDIA, и многие эксперты полагали, что она станет одним из главных бенефициаров бума ИИ. Однако она по-прежнему уступает по темпам развития NVIDIA, а заодно и своему основному конкуренту Broadcom, который разрабатывает чипы как минимум для четырёх гиперскейлеров. Покупка XConn призвана исправить ситуацию, дополняя недавнее приобретение Celestial AI. По словам Marvell, приобретение XConn добавит проверенные коммутационные продукты PCIe и CXL, IP-решения и инженерные кадры для расширения команды по масштабируемым коммутаторам UALink. «В сочетании с предстоящим приобретением Celestial AI мы будем иметь все возможности для предоставления клиентам производительности, гибкости и архитектурного выбора, необходимых им по мере роста размеров и сложности ИИ-систем», — отметил он. 
Источник изображения: XConn Сделка позволит Marvell расширить свой общий целевой рынок (Total Addressable Market, TAM) за счёт освоения растущих возможностей коммутаторов PCIe и CXL. PCIe-коммутаторы становятся критически важным строительным блоком для ИИ-инфраструктуры. В то же время CXL необходим для дезагрегации памяти в современных ЦОД. Сочетание контроллеров памяти Marvell CXL с коммутаторами XConn CXL позволит создать самый обширный в отрасли портфель коммутаторов для поддержки ресурсоёмких ИИ-задач. На данный момент у XConn насчитывается более чем 20 клиентов. Marvell ожидает, что продукты XConn CXL и PCIe начнут приносить доход во II половине 2027 финансового года. Также ожидается, что в результате сделки Marvell получит около $100 млн дополнительного дохода в 2028 финансовом году.
17.12.2025 [10:11], Сергей Карасёв
SK hynix и NVIDIA объединили усилия для создания сверхбыстрых SSD для ИИ-системКомпании SK hynix и NVIDIA, по сообщениям сетевых источников, занимаются совместной разработкой сверхбыстрых SSD, которые, как ожидается, помогут устранить узкие места современных ИИ-платформ. Проект получил название Storage Next: он предполагает создание чипов флеш-памяти NAND и сопутствующих контроллеров следующего поколения. По информации ресурса ZDNet, первые прототипы изделий партнёры намерены представить к концу следующего года. Речь идёт о накопителях с интерфейсом PCIe 6.0, которые смогут демонстрировать показатель IOPS (операций ввода/вывода в секунду) на уровне 25 млн. Более того, в 2027-м, как ожидается, будет выпущено устройство с величиной IOPS до 100 млн. Для сравнения, современные высокопроизводительные SSD корпоративного класса имеют значение IOPS на уровне 2–3 млн. 
Источник изображения: SK hynix В основу накопителей Storage Next лягут наработки SK hynix в области памяти AI-N (AI-NAND), оптимизированной для ИИ. В частности, упоминаются решения AI-N P: предполагается, что такие устройства будут выполнены в форм-факторе EDSFF E3.x. Они получат контроллер, предназначенный для выполнения как обычных рабочих нагрузок, так и с высоким показателем IOPS. По мере того, как ИИ-платформы переходят от обучения к инференсу, возможностей памяти HBM с высокой пропускной способностью оказывается недостаточно: наблюдается разрыв между объёмом и производительностью HBM и вычислительными возможностями ИИ-ускорителей на базе GPU. Цель проекта Storage Next состоит в том, чтобы решить эту проблему путём использования инноваций в области NAND. По сравнению с современными SSD накопители Storage Next смогут демонстрировать увеличение показателя IOPS в 30–50 раз. Кроме того, SK hynix разрабатывает память AI DRAM (AI-D) для ИИ-платформ: эти изделия, как предполагается, помогут справиться с нехваткой памяти.
02.12.2025 [09:39], Владимир Мироненко
Миллионы IOPS, без посредников: NVIDIA SCADA позволит GPU напрямую брать данные у SSDNVIDIA разрабатывает SCADA (Scaled Accelerated Data Access, масштабируемый ускоренный доступ к данным) — новую IO-архитектуру, где GPU инициируют и управляют процессом работы с хранилищами, сообщил Blocks & Files. SCADA отличается от существующего протокола NVIDIA GPUDirect, который, упрощённо говоря, позволяет ускорить обмен данными с накопителями, напрямую связывая посредством RDMA память ускорителей и NVMe SSD. В этой схеме CPU хоть и не отвечает за саму передачу данных, но оркестрация процесса всё равно ложится на его плечи. SCADA же предлагает перенести на GPU и её. Обучение ИИ-моделей обычно требует передачи больших объёмов данных за сравнительно небольшой промежуток времени. При ИИ-инференсе осуществляется передача небольших IO-блоков (менее 4 Кбайт) во множестве потоков, а время на управление каждой передачей относительно велико. Исследование NVIDIA показало, что инициирование таких передач самим GPU сокращает время и ускоряет инференс. В результате была разработана схема SCADA. NVIDIA уже сотрудничает с партнёрами по экосистеме хранения данных с целью внедрения SCADA. Так, Marvell отмечает: «Потребность в ИИ-инфраструктуре побуждает компании, занимающиеся СХД, разрабатывать SSD, контроллеры, NAND-накопители и др. технологии, оптимизированные для поддержки GPU, с акцентом на более высокий показатель IOPS для ИИ-инференса. Это будет принципиально отличаться от технологий для накопителей, подключенных к CPU, где главными приоритетами являются задержка и ёмкость». 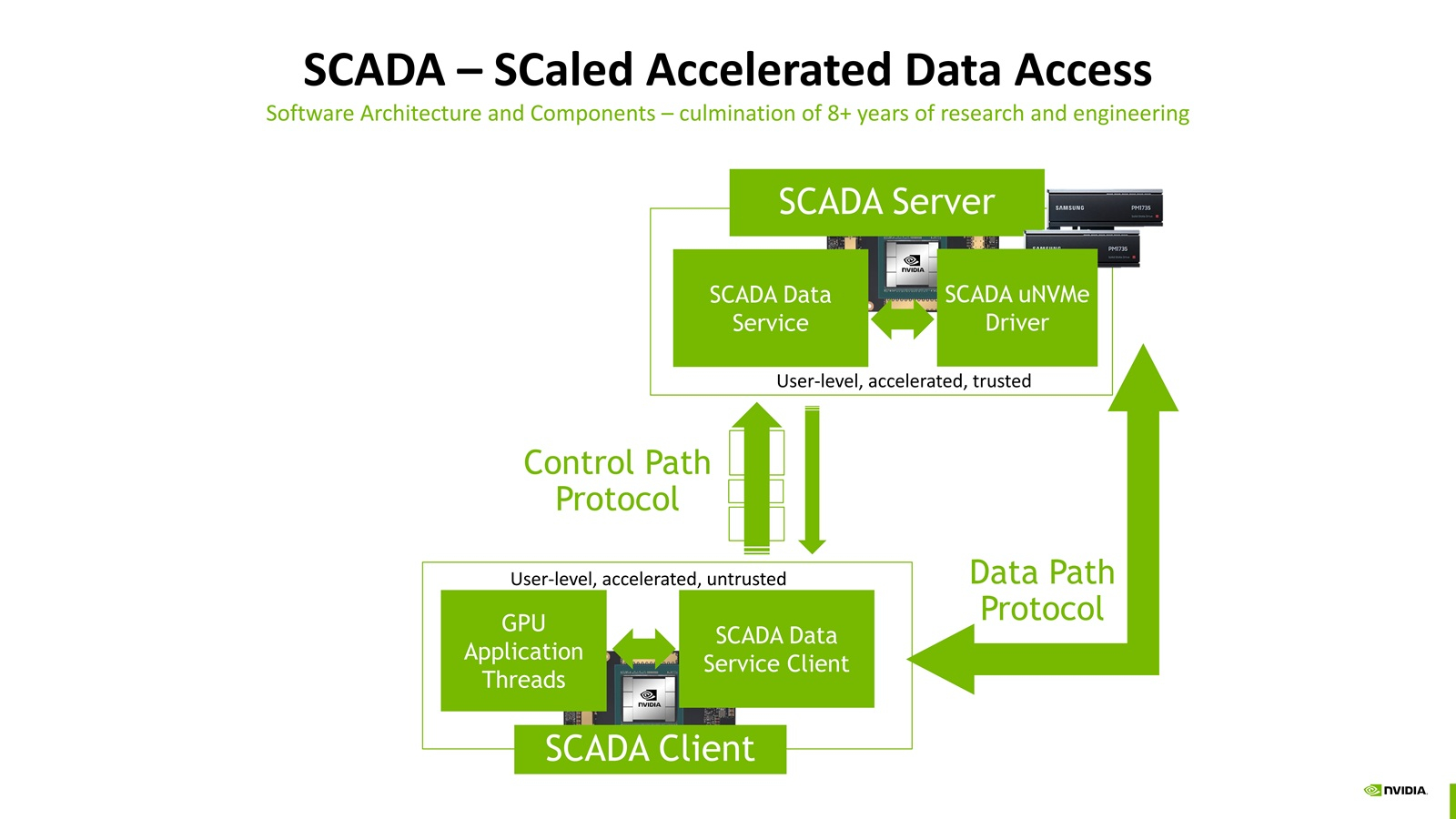
Источник изображения: NVIDIA По словам Marvell, в рамках SCADA ускорители используют семантику памяти при работе с накопителями. Однако сами SSD мало подходят для таких задач, поскольку не могут обеспечить необходимый уровень IOPS, когда во время инференса тысячи параллельных потоков запрашивают наборы данных размером менее 4 Кбайт. Это приводит к недоиспользованию шины PCIe, «голоданию» GPU и пустой трате циклов. В CPU-центричной архитектуре, которая подходит для обучения моделей, параллельных потоков данных десятки, а не тысячи, а блоки данных крупные — от SSD требуется высокие ёмкость и пропускная способность, а также малая задержка, поскольку свою задержку в рамках СХД также внесут PCIe и Ethernet. Внедрение PCIe 6.0 и PCIe 7.0, конечно, само по себе ускорит обмен данными, но контроллеры SSD также нуждаются в обновлении. Они должны уметь использовать возможности SCADA, иметь оптимальные схемы коррекции ошибок для малых блоков данных и быть мультипротокольными (PCIe, CXL, Ethernet). Компания Micron также участвует в разработке SCADA. 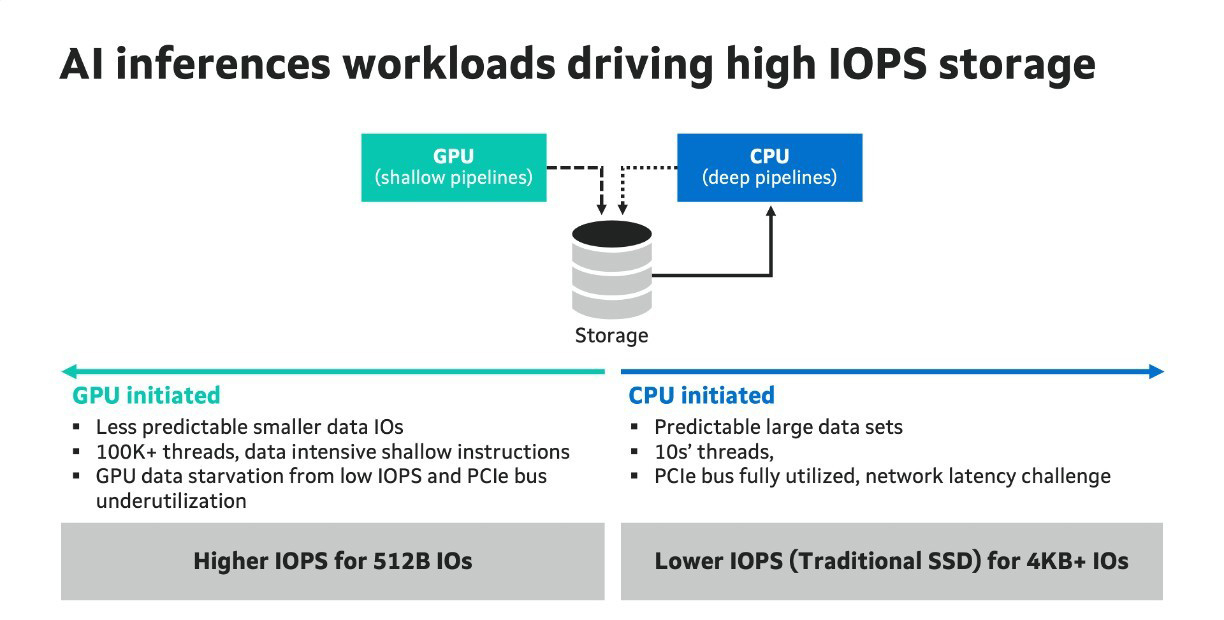
Источник изображения: Micron В рамках SC25 Micron показала прототип SCADA-хранилища на базе платформы H3 Platform Falcon 6048 с PCIe 6.0 (44 × E1.S NVMe SSD + 6 × GPU/DPU/NIC), оснащённой 44 накопителями Micron 9650 (7,68 Тбайт, до 5,4 млн на случайном чтении 4K-блоками с глубиной очереди 512, PCIe 6.0), тремя коммутаторами Broadcom PEX90000 (144 линии PCIe 6.0 в каждом), одним процессором Intel Xeon (PCIe 5.0) и тремя ускорителями NVIDIA H100 (PCIe 5.0). Micron заявила, что система «демонстрирует линейное масштабирование производительности от 1 до 44 SSD», доходя до 230 млн IOPS, что довольно близко к теоретическому максимуму в 237,6 млн IOPS. «В сочетании с PCIe 6.0 и высокопроизводительными SSD архитектура [SCADA] обеспечивает доступ к данным в режиме реального времени для таких рабочих нагрузок, как векторные базы данных, графовые нейронные сети и крупномасштабные конвейеры инференса», — подытожила Micron.
30.10.2025 [13:51], Владимир Мироненко
От Nearline SSD до HBF: SK hynix анонсировала NAND-решения AIN для ИИ-платформКомпания SK hynix представила стратегию развития решений хранения на базе NAND нового поколения. SK hynix заявила, что в связи с быстрым ростом рынка ИИ-инференса спрос на хранилища на базе NAND, способных быстро и эффективно обрабатывать большие объёмы данных, стремительно растёт. Для удовлетворения этого спроса компания разрабатывает серию решений AIN (AI-NAND), оптимизированных для ИИ. Семейство будет включать решения AIN P, AIN B и AIN D, оптимизированные по производительности, пропускной способности и плотности соответственно. 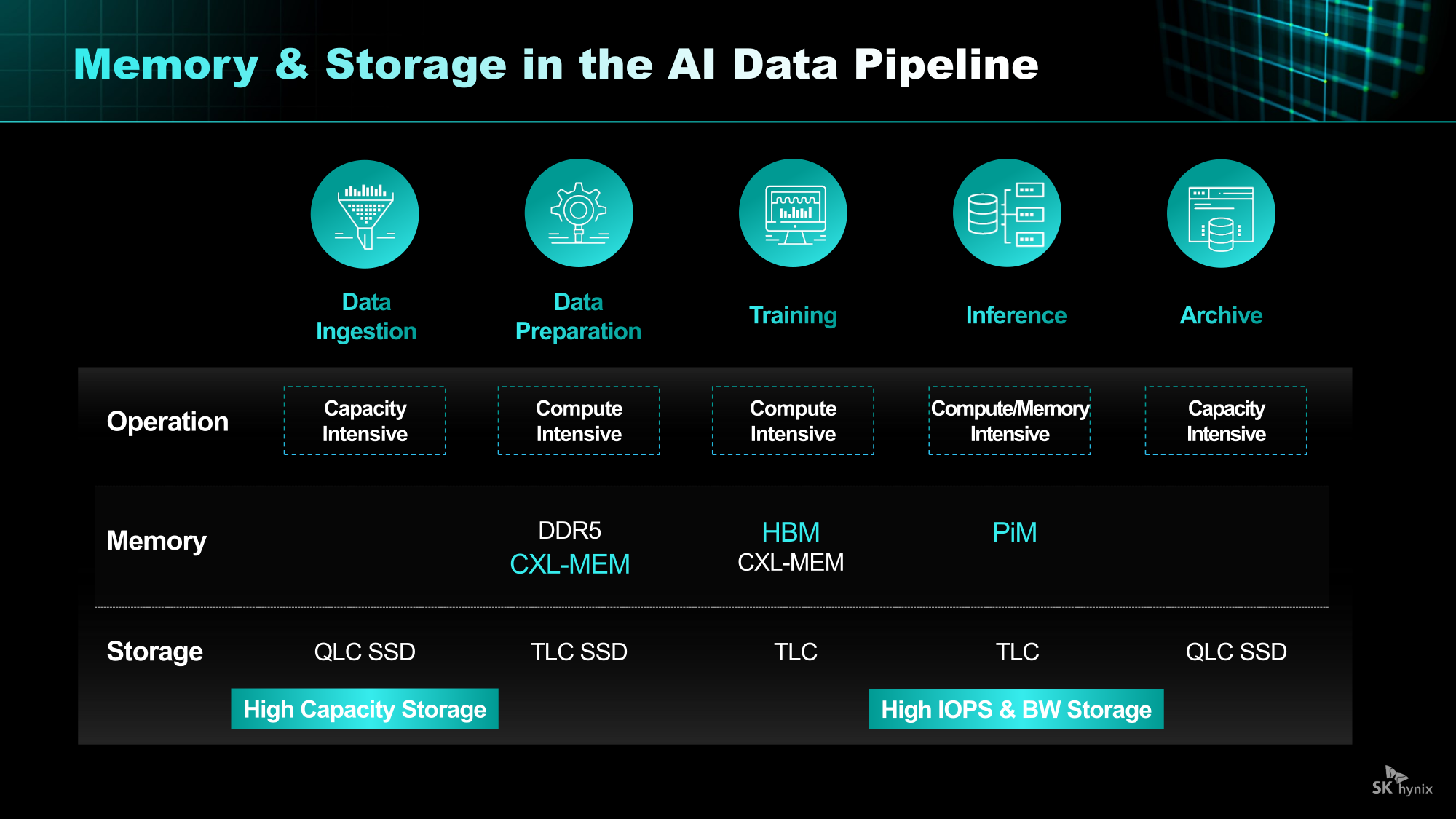
Источник изображений: SK hynix AIN P (Performance) — это решение для эффективной обработки больших объёмов данных, генерируемых в рамках масштабных рабочих нагрузок ИИ-инференса. Продукт значительно повышает скорость обработки и энергоэффективность, минимизируя узкие места между хранилищем и ИИ-операциями. SK hynix разрабатывает NAND-память и контроллеры с новыми возможностями и планирует выпустить образцы к концу 2026 года.  Как пишет Blocks & Files, накопитель AIN P, как ожидается, получит поддержку PCIe 6.0 и обеспечит 50 млн IOPS на 512-байт блоках, тогда как сейчас производительность случайного чтения и записи с 4-Кбайт блоками составляет порядка 7 млн IOPS у накопителей PCIe 6.0. То есть AIN P будет в семь раз быстрее, чем нынешние корпоративные PCIe 6.0 SSD, и, по заявлению SK hynix, достичь 100 млн IOPS можно будет уже в 2027 году. Такой SSD будет выполнен в форм-факторе EDSFF E3.x и оснащён контроллером, предназначенным для выполнения как обычных рабочих нагрузок, так и с высоким показателем IOPS. 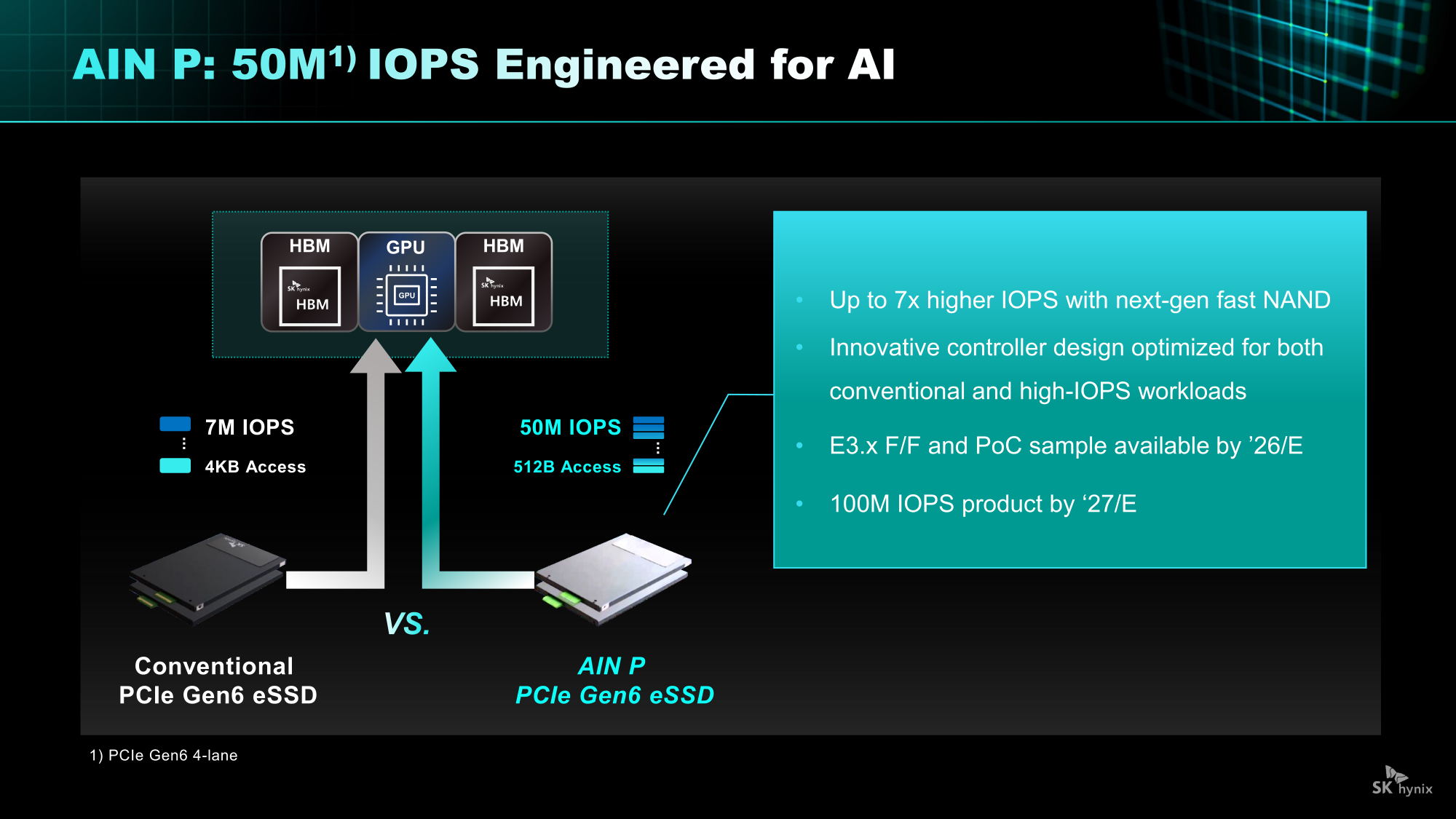 AIN D (Density) — это высокоплотное решение Nearline (NL) SSD для хранения больших объёмов данных с низкими энергопотреблением и стоимостью, подходящее для хранения ИИ-данных. Компания стремится увеличить плотность QLC SSD с Тбайт до Пбайт, создав решение среднего уровня, сочетающее в себе скорость SSD и экономичность HDD. AIN D от SK hynix как раз предназначен для замены жёстких дисков. Компания также упоминает некий стандарт JEDEC-NLF (Near Line Flash?), который пока не существует. При этом SK hynix пока не упоминает PLC NAND и не приводит данные о ёмкости AIN D.  AIN B (Bandwidth) — это HBF-память с увеличенной за счёт вертикального размещения нескольких модулей NAND пропускной способностью. Ключевым в данном случае является сочетание структуры стекирования HBM с высокой плотностью и экономичностью флеш-памяти NAND. AIN B предложит большую ёмкость, чем HBM, примерно на уровне ёмкости SSD. AIN B может увеличить эффективную ёмкость памяти GPU и, таким образом, устранить необходимость покупки/аренды дополнительных GPU для увеличения ёмкости HBM, например, для хранения содержимого KV-кеша. 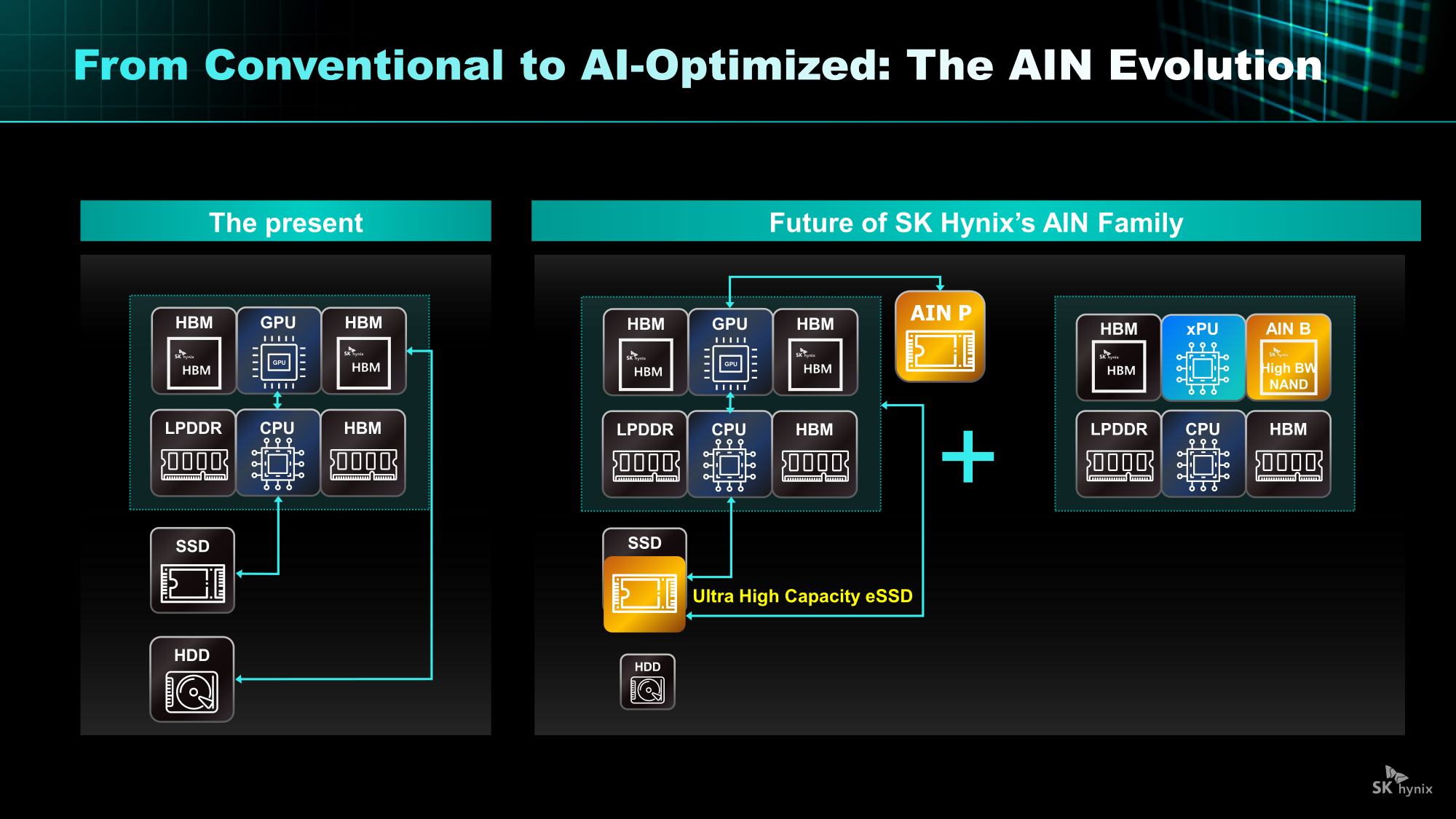 Компания рассматривает различные стратегии развития AIN B, например, совместное использование с HBM для повышения общей ёмкости системы, поскольку стек HBF может быть совмещён со стеком HBM на одном интерпозере. SK hynix и Sandisk работают над продвижением стандарта HBF. Они провели в рамках 2025 OCP Global Summit мероприятие HBF Night, посвящённое этому вопросу. Рании компании подписали меморандум о стандартизации HBF в целях расширения технологической экосистемы. 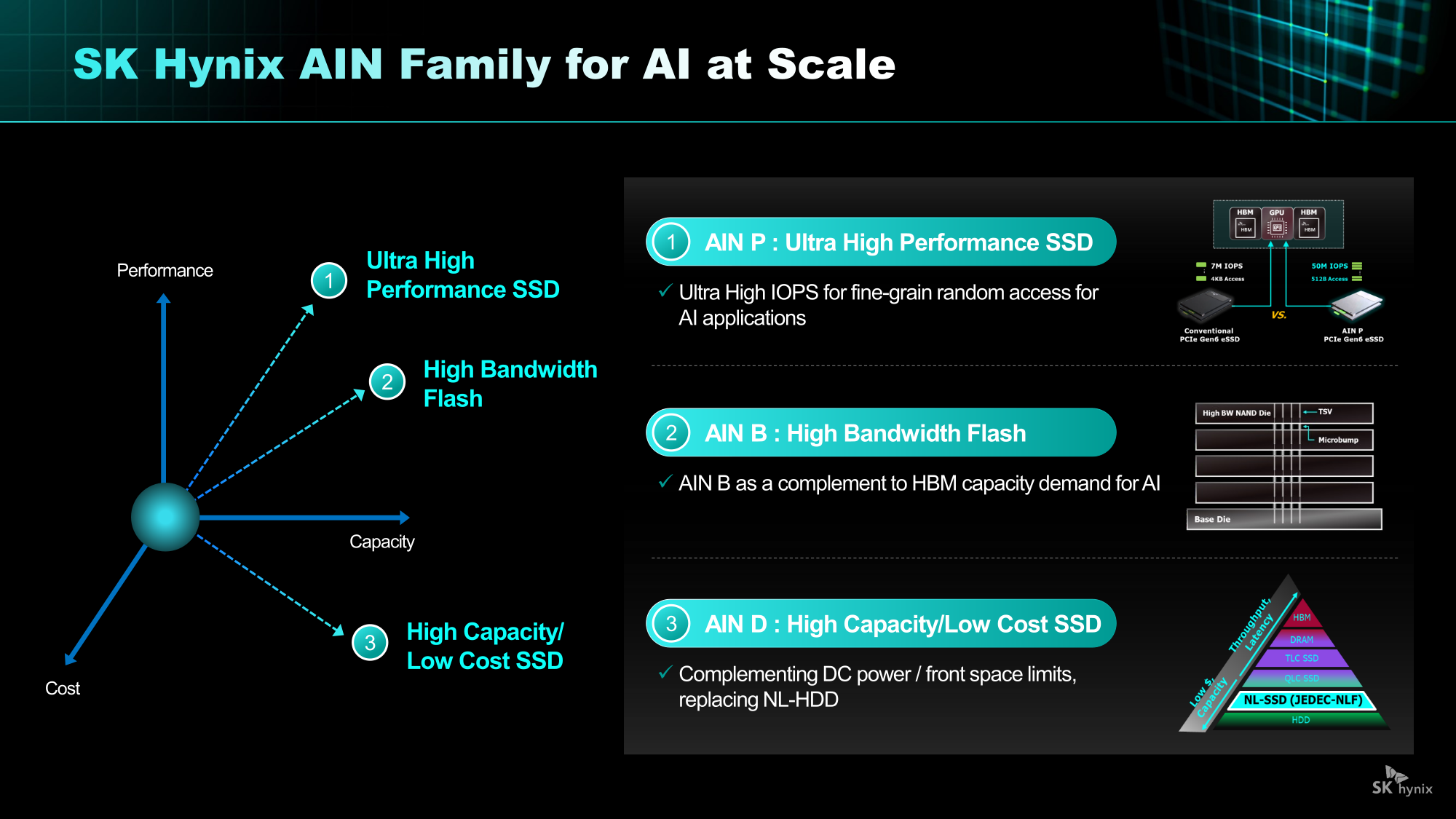 «Благодаря OCP Global Summit и HBF Night мы смогли продемонстрировать настоящее и будущее SK hynix как глобального поставщика решений памяти, процветающего на быстро развивающемся ИИ-рынке», — заявила SK hynix, добавив, что на рынке устройств хранения данных на базе NAND следующего поколения SK hynix будет тесно сотрудничать с клиентами и партнёрами, чтобы стать ключевым игроком.
28.10.2025 [20:35], Сергей Карасёв
NVIDIA анонсировала DPU BlueField-4: 800G-порты, ConnectX-9, CPU Grace и PCIe 6.0NVIDIA анонсировала DPU BlueField 4, рассчитанный на использование в составе масштабных инфраструктур ИИ. Устройство оснащено 800G-портами. Новинка в этом отношении вдвое быстрее BlueField-3, дебютировавших ещё в 2021 году. NVIDIA отмечает, что ИИ-фабрики продолжают развиваться с беспрецедентной скоростью. При этом требуется обработка колоссальных массивов структурированных и неструктурированных данных. Для удовлетворения этих потребностей необходимо формирование инфраструктуры нового класса, на которую как раз и ориентирован DPU BlueField-4. Новинка использует программно-определяемую архитектуру для ускорения сетевых операций, функций безопасности и задач хранения данных. По заявлениям NVIDIA, BlueField-4 позволяет трансформировать дата-центры в безопасную интеллектуальную ИИ-инфраструктуру с высокой производительностью. BlueField-4 объединяет 64-ядерный Arm-процессор NVIDIA Grace (114 Мбайт L3-кеш), 128 Гбайт LPDDR5, 512 Гбайт SSD, сетевой адаптер NVIDIA ConnectX-9 SuperNic (1,6 Тбит/с), а также коммутатор PCIe 6.0 с 48 линиями. Новинка будет доступна в виде карты расширения (PCIe 6.0 x16) и в виде модуля для узлов VR NVL144. Утверждается, что по сравнению с BlueField-3 вычислительная производительность выросла в шесть раз. При этом возможно формирование ИИ-фабрик вчетверо большего масштаба. Кроме того, BlueField-4 поддерживает многопользовательскую сеть, быстрый доступ к данным и микросервисы NVIDIA DOCA. Задействована архитектура NVIDIA BlueField Advanced Secure Trusted Resource Architecture. 
Источник изображения: NVIDIA Предполагается, что BlueField-4 возьмут на вооружение такие производители серверов и платформ хранения данных, как Cisco, DDN, Dell Technologies, HPE, IBM, Lenovo, Supermicro, VAST Data и WEKA. О поддержке новинки заявили Armis, Check Point, Cisco, F5, Forescout, Palo Alto Networks и Trend Micro, а также системные интеграторы Accenture, Deloitte и World Wide Technology. Интегрировать BlueField-4 в свои платформы намерены Canonical, Mirantis, Nutanix, Rafay, Red Hat, Spectro Cloud и SUSE. На рынок BlueField-4 поступит в 2026 году как часть экосистемы Vera Rubin.
22.10.2025 [17:09], Владимир Мироненко
AWS пожертвовала компактностью GB300 NVL72, лишь бы снизить зависимость от NVIDIAAmazon Web Services (AWS) нашла выход, как использовать собственные Nitro DPU K2v5/6 (EFA) в новейших стоечных системах NVIDIA GB300 NVL72, которые, как считает гиперскейлер, превосходит адаптеры NVIDIA ConnectX-7/8 по производительности. В связи с тем, что в стойках NVIDIA Oberon используются укороченные лотки высотой 1U, AWS размещает NIC в отдельной стойке JBOK, предназначенной только для сетевых карт, пишет SemiAnalysis. Причина кроется в невозможности установить в 1U сразу девять фирменных адаптеров (8 × EFA + 1 × ENA/EBS). Для серверных систем GB200 NVL предыдущего поколения AWS выбрала вариант NVL36×2, поскольку только в этом случае использовались 2U-узлы, где достаточно места для всех NIC. Однако сдвоенная конфигурация менее эффективна, чем нативная конструкция NVL72. NVIDIA сама была не очень довольна вариантами NVL36. Meta✴, например, и вовсе «растянула» NVL36×2 на шесть стоек, чтобы обойтись воздушным охлаждением. 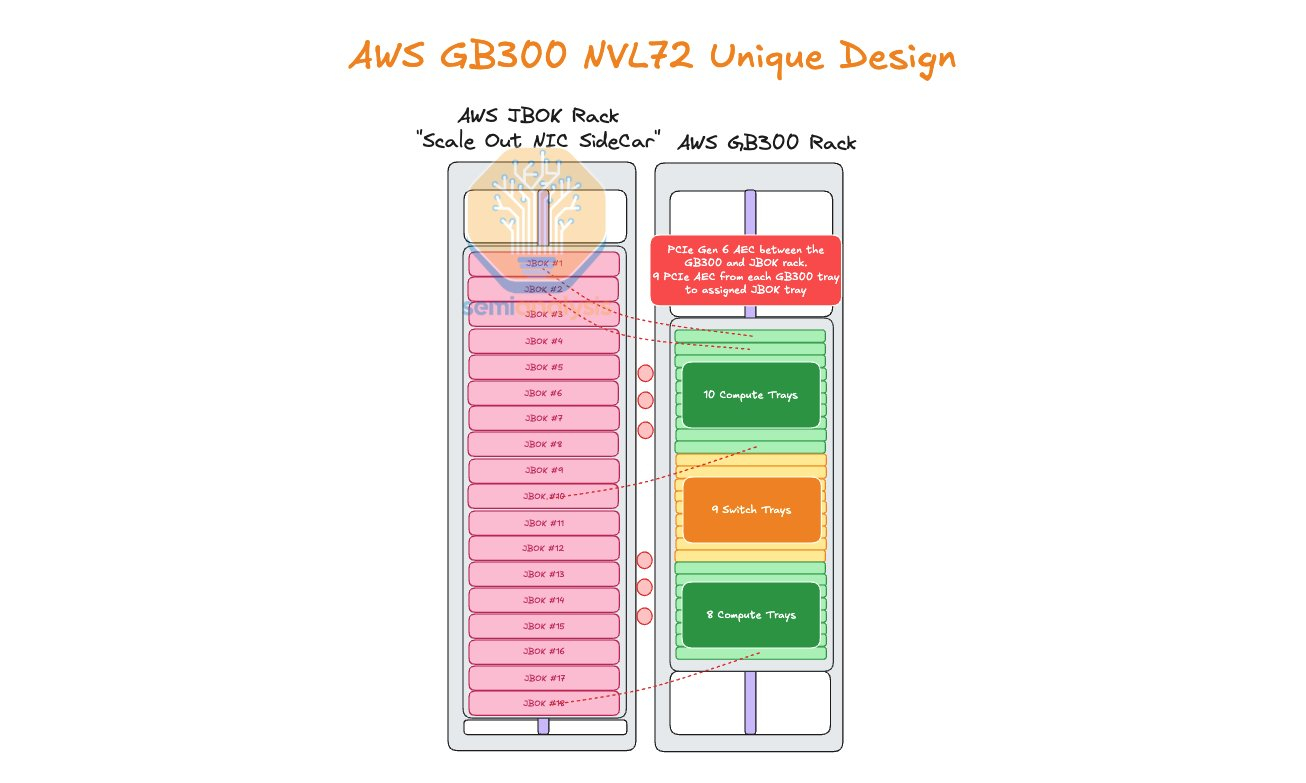
Источник изображения: SemiAnalysis AWS в случае Blackwell Ultra предпочла остановиться на NVL72-варианте, а DPU вынести в отдельную стойку — всего 18 узлов высотой 2U, по 9 NIC в каждом. С узлами NVIDIA они соединены активными электрическими кабелями (AEC) и портами OSFP-XD для передачи сигналов PCIe 6.0. По словам AWS, её адаптеры лучше справляются с нагрузками, чем ConnectX-8 (RoCEv2), что отчасти спорно. В любом случае таким образом компания снижается зависимость от NVIDIA. 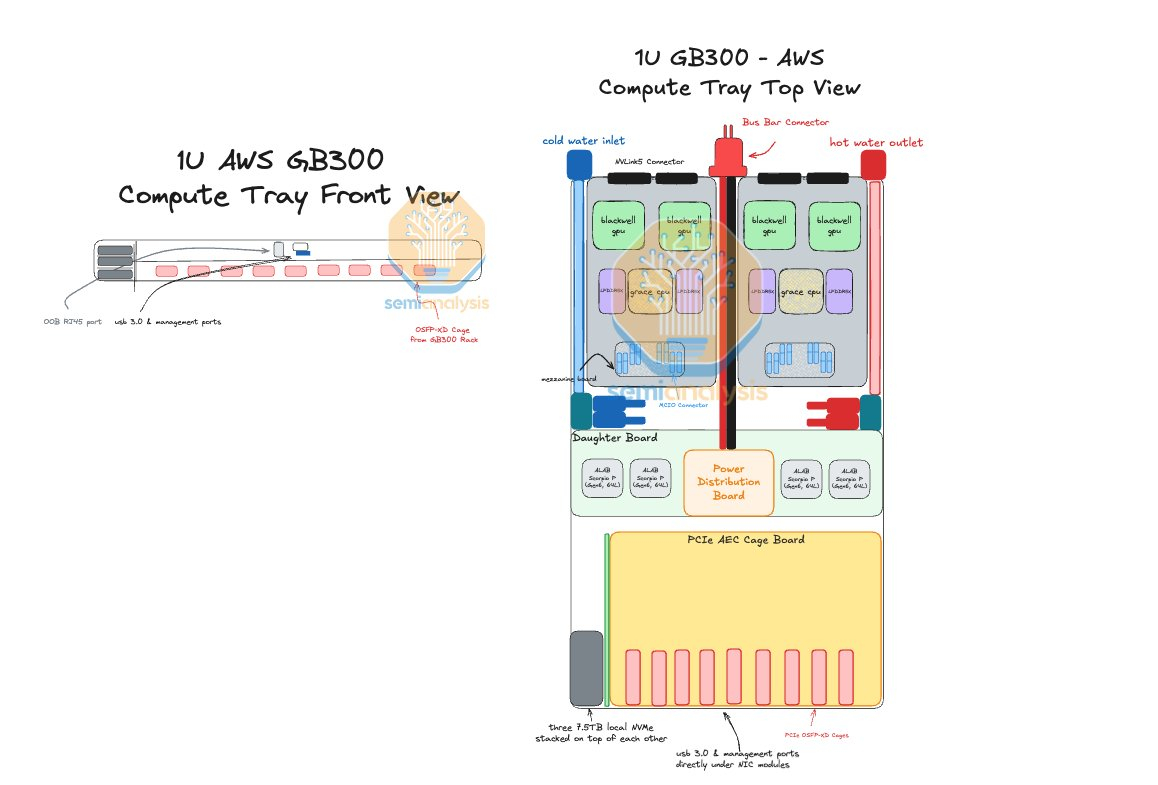
Источник изображения: SemiAnalysis С точки зрения SemiAnalysis, доработка GB300 в AWS помогает устранить единую точку отказа в референсной архитектуре NVIDIA, где каждый ускоритель взаимодействует только с одним сетевым адаптером ConnectX-8, тогда как в конфигурации AWS каждый ускоритель общается с двумя NIC. У AWS накоплен богатый опыт разработки собственного оборудования для ЦОД. Ранее компания в партнёрстве с Broadcom разрабатывала специализированные сетевые коммутаторы. Также недавно представленные ею EC2-инстансы P6-B200 и P6e-GB200 оснащены собственным сетевым стеком Elastic Fabric Adapter (EFAv4) на базе собственных контроллеров Nitro, который оптимизирует обработку сетевых пакетов и снижает задержки для высокопроизводительных приложений.
15.10.2025 [14:00], Сергей Карасёв
Broadcom представила первые в мире 800GbE-адаптеры Thor Ultra с поддержкой Ultra Ethernet для масштабных ИИ-кластеровКомпания Broadcom анонсировала изделия Thor Ultra: это, как утверждается, первые в отрасли сетевые Ethernet-адаптеры (NIC) стандарта 800G, которые могут использоваться в составе масштабных ИИ-кластеров, объединяющих сотни тысяч ускорителей XPU для обработки моделей с триллионами параметров. Изделия выполнены в соответствии с открытой спецификацией Ultra Ethernet Consortium (UEC). Реализованы передовые возможности RDMA, включая многоканальное распределение на уровне пакетов для эффективной балансировки нагрузки, избирательную ретрансляцию для высокопроизводительной передачи данных, доставку пакетов вне очереди напрямую в память XPU, а также программируемые алгоритмы управления перегрузкой на уровне отправителя и получателя. 
Источник изображений: Broadcom Адаптеры Thor Ultra доступны в виде карт PCIe и OCP 3.0. Используется хост-интерфейс PCIe 6.0 x16. Реализован один порт с возможностью использования в режимах 800/400/200/100G/50/25GbE. Допускается шифрование и дешифрование данных на линейной скорости, что освобождает CPU/XPU от ресурсоёмких вычислительных задач. Благодаря применению 200G/100G PAM4 SerDes обеспечивается большая дальность пассивного медного соединения.  В качестве ключевых сфер использования названы серверы для задач ИИ и машинного обучения, публичные и частные облачные платформы, высокопроизводительные серверы хранения, а также системы HPC. Адаптеры Thor Ultra совместимыми с такими коммутационными решениями, как Broadcom Tomahawk 6. Упомянуты развитые функции телеметрии и обеспечения безопасности. |
|

